
Changing face of Algorithms
3AI April 12, 2021

In the age of Big Data, algorithms give companies a competitive advantage. Today’s most important technology companies all have algorithmic intelligence built into the core of their product: Google Search, Facebook News Feed, Amazon’s and Netflix’s recommendation engines.
“Data is inherently dumb,” Peter Sondergaard, senior vice president at Gartner and global head of Research, said in The Internet of Things Will Give Rise To The Algorithm Economy. “It doesn’t actually do anything unless you know how to use it.”
For many technology companies, they’ve done a good job of capturing data, but they’ve come up short on doing anything valuable with that data. Thankfully, there are fundamental shifts happening in technology right now that are leading to the democratization of algorithmic intelligence, and changing the way we build and deploy smart apps today.
Container Based Analytics Computing
The confluence of the algorithm economy and containers creates a new value chain, where algorithms as a service can be discovered and made accessible to all developers through a simple REST API. Algorithms as containerized microservices ensure both interoperability and portability, allowing for code to be written in any programming language, and then seamlessly united across a single API.
By containerizing algorithms, we ensure that code is always “on,” and always available, as well as being able to auto-scale to meet the needs of the application, without ever having to configure, manage, or maintain servers and infrastructure. Containerized algorithms shorten the time for any development team to go from concept, to prototype, to production-ready app.
Algorithms running in containers as microservices is a strategy for companies looking to discover actionable insights in their data. This structure makes software development more agile and efficient. It reduces the infrastructure needed, and abstracts an application’s various functions into microservices to make the entire system more resilient. This can be leveraged to build a marketplace platform fostering Algorithm Economy. The algorithm economy also allows for the commercialization of world class research that historically would have been published, but largely under-utilized. In the algorithm economy, this research is turned into functional, running code, and made available for others to use. The ability to produce, distribute, and discover algorithms fosters a community around algorithm development, where creators can interact with the app developers putting their research to work.
Mesh Apps in Analytics
The mesh app and service architecture (MASA) is a multichannel solution architecture that supports multiple users in multiple roles using multiple devices and communicating over multiple networks to access application functions. Monolithic applications will be refactored into reusable microservices and shared modular miniservices that reduce the scope of a service down to an individual capability.
The current software ecosystem allows only whole products to be commercialized — not functions or features. Obviously this conventional wisdom ends with algorithm marketplaces, given that software distribution costs become marginal. Seeing this diversity of components offered today, the term “algorithm” may become too narrow in future.
Several advanced Analytics tools are being either created from scratch or refactored into “mesh apps” which basically are an interconnected functioning of analytics microservices and miniservices. This makes sure that the analytics apps and miniservices conform “re-usable commercial asset”, part of the Algorithm Marketplace, catering to one of the stages of Analytics Pipeline. Figure below demonstrates the range of analytics algorithms that are being commercialized by the early algorithm marketplaces. These include data services, wrappers and preparation components, and data science models, right up to whole solutions for specific contexts.
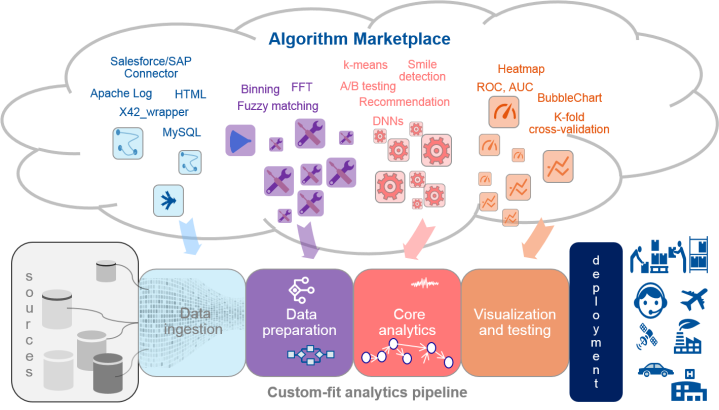
Internet of Anything Analytics
In 2016, businesses will look at deriving algorithmic value from all data. It’s not just the Internet of Things but rather Internet of Anything that can provide insights. Getting value from data extends beyond devices, sensors and machines and includes all data including that produced by server logs, geo location and data from the Internet.
Businesses must look beyond the edge of their data centers all the way out to the jagged edge of data. Data flows now originate outside the data from many devices, sensors and servers on — for example, an oil rig in the ocean or a satellite in space. There is a huge opportunity to manage the security perimeter as well as to provide complete data provenance across the ecosystem. IoAT Analytics creates a new paradigm that requires new thinking and new data management systems, and these solutions will mature and permeate the enterprise in 2017.
Data in Motion Platform
The industry will see the evolution of data in motion platforms in 2017. There is a need for a higher-level platform to handle the many device protocols and bring all of the data flows into Hadoop. The platform needs to facilitate communications in multiple protocol languages. There combination of data in motion and data at rest is a big opportunity for the year.
There is a market need to simplify big data technologies, and opportunities for this exist at all levels: technical, consumption and so on. In 2017 there will be significant progress toward simplification. It doesn’t matter who you are — cluster operator, security administrator, data analyst — everyone wants Hadoop and related big data technologies to be straightforward. Big Data is not the aspiring norm anymore but just a foundational base for algorithm building. Things like a single integrated developer experience or a reduced number of settings or profiles will start to appear across the board.
Single Node Analytics Techniques over Multinode
By 2018, single-node analytics with Spark will predominate over multinode Hadoop-based architectures
The overwhelming majority of advanced analytics modeling consists of interactively interrogating data, integrating data on an ad hoc basis, and performing numerical optimization. This work requires consistently high performance, which is often difficult to achieve in the multinode, distributed environment popularized by Hadoop distributions.
Apache Spark is becoming increasingly popular for data processing tasks such as analytics, machine learning, and interactive data exploration through open-source dashboard tools like Jupyter Notebook and Apache Zeppelin. However, Apache Spark remains challenging to manage in a distributed environment, and its resource-intensive nature makes it a poor choice in mixed workload environments. Highly optimized single-node servers, perhaps using field-programmable gate arrays (FPGAs) or powerful graphics processing units (GPUs), are increasingly available at attractive price points. These dedicated resources avoid multi workload performance and optimization conflicts, while offering better performance for computing- and memory-intensive data science and analytics tasks.
Today, multinode clusters are not well-suited to the inner advanced analytics modeling steps, which require consistently high performance. The intensive nature of this advanced analytics model selection inner loop often causes disruptive workloads for the whole cluster. Containment strategies of advanced analytics to a few nodes are not ideal, as this requires tedious data movement and is still stuck with unpredictable node chatter. Instead, we see that most data scientists still prefer fat single-node deployments. Consequentially, single-node and multinode deployments of Spark/Hadoop will coexist to support different use-case scenarios. Many advanced analytics scenarios will continue to require single node deployments that benefit from fat servers with lots of RAM, many cores, and lots of clock speed or specialized scenarios.
Enhanced Causality between Data, Analytics, Trust & Business Outcomes
Predictive analytics based on probabilistic methods and prescriptive algorithms are proliferating due to the growth of the digital business. Algorithmic business is the engine of automated action in the digital economy. Using data for analytics purposes has an impact on people’s choices and behaviors, and the interactions between parties. Bad interactions can erode trust very quickly, and mishandling of analytics can foster distrust. Regaining that trust can be difficult — sometimes even irrecoverable — so its loss can set back what can be substantial investments in creating a data-driven culture. Worse, the underlying factors of fostering trusted business relationships based on data are seldom even given much, if any, consideration, and the associated security, commercial and reputational risk factors are either ignorantly, carelessly, or negligently ignored (and in some cases, even willfully ignored). The resulting impacts are tangible: unrealized business opportunities, additional inefficiencies, increased brand risk, and even criminal proceedings.
The trust factors influencing the ethical use of analytics are identifiable — transparent, accountable, understandable, mindful, palatable, and mutually. Yet, the resulting business, social and ethical impacts arising from the use of data and analytics are understood by few, ignored by many, and tracked by virtually no one.
Leading data-driven organizations will increasingly recognize the causal relationships between data, analytics, trust and business outcomes. Those organizations that choose proactively to govern these ethical impacts will be able to foster more productive and trusted relationships with their customers, suppliers, and employees; drive increased competitive advantage and brand loyalty, and maximize their market share in comparison to competitors that do not address these issues.




