
As a relatively new – but already highly sought after – position, it can be hard to know where Data Analytics ends and Data Science begins. Is it science? Statistics? Programming? Analytics? Black magic? Or some strange and wonderful combination? Making the most of this digital goldmine to optimize outcomes and meet business goals requires some very advanced skills that many organizations don’t yet have within their ranks. But what type of data professionals are needed? Does an organization need a data scientist, or does it need a data analytics professional? Or does it need both? Although these two titles are often used interchangeably, they’re definitely not the same.

Extending the Maturity Curve using Data Science
Valve software – a software company in Seattle that makes computer games – has a good definition of their ideal employee. It’s this “T” shape employee who is a generalist in variety of different areas but has deep a domain experience in one vertical.
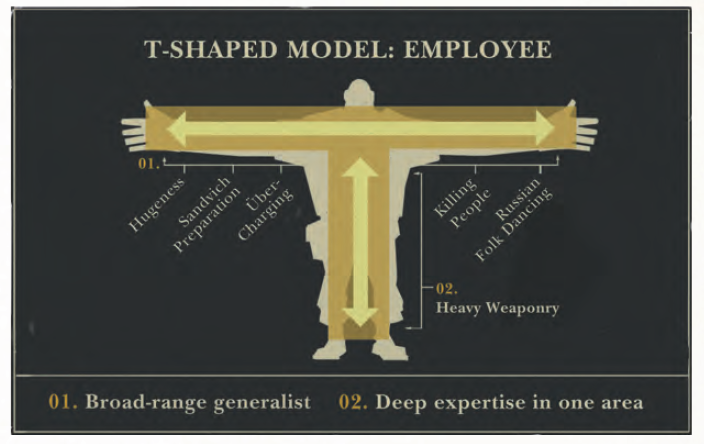
That’s how we should think of Data Scientists as well.
A Data Scientist should have a wide breadth of abilities: academic curiosity, storytelling, product sense, engineering experience and just a catch-all I call cleverness. But he or she should also have deep domain expertise in Statistical and Machine Learning Knowledge.
Imbibe Academic curiosity
To me, academic curiosity is a desire to go beneath the surface and distill a problem into a very clear set of hypotheses that can be tested. Much like how scientists in the research lab will have a very amorphous charter of improving science, data scientists in a company, will have an amorphous charter of improving the product somehow.
He or she will use this academic curiosity to look at the available data sets and sources to figure out an experiment or a model that solves one of the company’s problems.
Scale up on the art of Storytelling
Storytelling is the ability to communicate your findings effectively to non technical stakeholders.
For example, Mosaic took the entire UK population and ran a machine learning model over it. Based on what they found, they were able to split the entire UK population into 61 clusters. But if you have 61 different clusters, you need a good (easy to explain way) to differentiate between each cluster.
One of those categories is called Golden Empty Nesters, which is a good title because without me explaining anything to you, it evokes some sort of image about the person who would fit into it. Specifically, they are financially secure couples, many close to retirement, living in sought after suburbs.
This ability to distill a quantitative result from a machine learning model into something (be it words, pictures, charts, etc) that everyone can understand immediately is actually a very important skill for data scientists.
Instill “Product sense”, even in services
Product sense is the ability to use the story to create a new product or change an existing product in a way that improves company goals and metrics.
In Data Science, say, at Amazon, it’s not enough to have built a collaborative filter to create a recommendation engine, you should also know how to mold it into a product. For example, the “customers who bought this item also bought” section is an 800 by 20 pixel box which outlines the result of this machine learning model in a way that is visually appealing to customers.
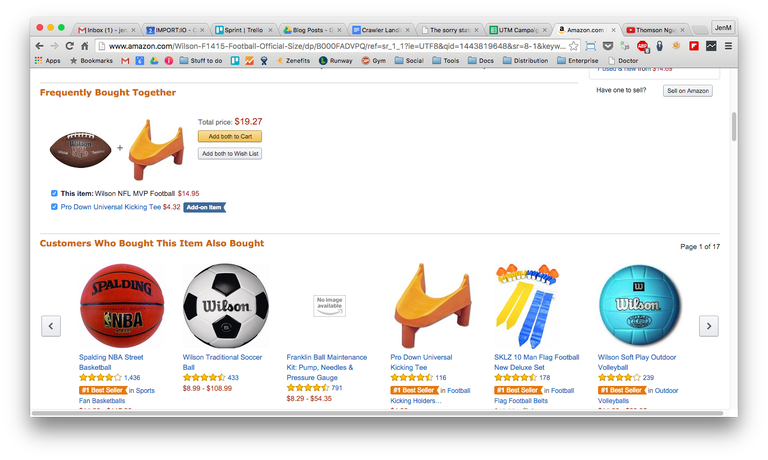
Even if you’re not the product manager – or the engineer that creates these products – as a Data Scientist, whatever you create, in code or in algorithms, will need to translate into one of these products. So having a good sense of what that might look like, unlike in Analytics where only operative analysis knowledge gets you through, will get you a long way.
Implement Statistical and machine learning knowledge
Statistical and machine learning knowledge is the domain expertise required to acquire data from different sources, create a model, optimize its accuracy, validate its purpose and confirm its significance. This is the deep domain expertise that is required and developed once we make the move from Analytics to Data Science.
Introduce Data Engineering Expertise
Data Engineering Experience refers to the coding chops necessary to implement and execute statistical models.
For a lot of big companies this means knowing intense amounts of Scala, Java, Closure, ect to deploy your models into production. For startups this can be as simple as implementing a model in R.
Consequently, R is a great language for scaffolding models and visualization, but it’s not so great for writing production ready code – it breaks whenever you throw anything more than 10 megabytes in front of it.
But, it’s a great language to set up a proof of concept, and the ability to create something out of nothing and to prove that it works, is a skill that I think is a must in Data Science, unlike Analytics where operating via tool is enough without the need for creating statistical structures or routines.
India’s largest platform for AI & Analytics leaders, professionals & aspirants
3AI is India’s largest platform for AI & Analytics leaders, professionals & aspirants and a confluence of leading and marquee AI & Analytics leaders, experts, influencers & practitioners on one platform.
3AI platform enables leaders to engage with students and working professionals with 1:1 mentorship for competency augmentation and career enhancement opportunities through guided learning, contextualized interventions, focused knowledge sessions & conclaves, internship & placement assistance in AI & Analytics sphere.
3AI works closely with several academic institutions, enterprises, learning academies, startups, industry consortia to accelerate the growth of AI & Analytics industry and provide comprehensive suite of engage, learn & scale engagements and interventions to our members. 3AI platform have 16000+ active members from students & working professionals community, 500+ AI & Analytics thought leaders & mentors and an active outreach & engagement with 430+ enterprises & 125+ academic institutions.