
The Morphing of Analytics to Data Sciences
3AI January 4, 2021

As a relatively new – but already highly sought after – position, it can be hard to know where Data Analytics ends and Data Science begins. Is it science? Statistics? Programming? Analytics? Or some strange and wonderful combination?
I think a lot of the ambiguity – and some of the animosity – is simply because it’s such a new term and a new field. It’s not like being a Data Analyst or a BI Analyst, we’ve had 20 years to understand those job roles. Complicating the problem is that lots of companies have different definitions of what a data scientist is and what they do.
The current working definitions of Data Analytics and Data Science are inadequate for most organizations. But in order to think about improving their characterizations, we need to understand what they hope to accomplish. Data analytics seeks to provide operational observations into issues that we either know we know or know we don’t know. Descriptive analytics, for example, quantitatively describes the main features of a collection of data. Predictive analytics, that focus on correlative analysis, predicts relationships between known random variables or sets of data in order to identify how an event will occur in the future. For example, identifying the where to sell personal power generators and the store locations as a function of future weather conditions (e.g., storms). While the weather may not have caused the buying behavior, it often strongly correlates to future sales.
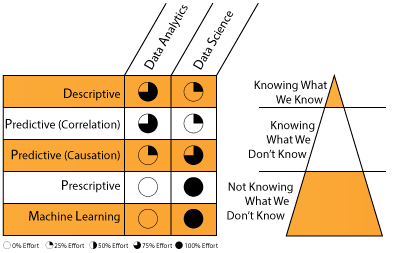
The goal of Data Science, on-the-other-hand, is to provide strategic actionable insights into the world were we don’t know what we don’t know. For example, trying to identify a future technology that doesn’t exist today, but will have the most impact on an organization in the future. Predictive analytics in the area of causation, prescriptive analytics (predictive plus decision science), and machine learning are three primary means through which actionable insights can be found. Predictive causal analytics precisely identifies the cause for an event, take for example the title of a film’s impact on box office revenue. Prescriptive analytics couples decision science to predictive capabilities in order to identify actionable outcomes that directly impact a desired goal.
The Relative Sophistication of Data Science
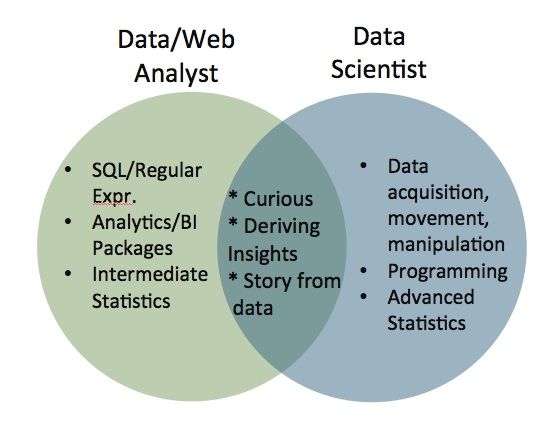
This Venn diagram (above) is a good first cut at describing how the two jobs overlap and how they differ. Data analysts are generally well versed in Sequel, they know a some Regular Expressions, they can slice and dice data, they can use analytics or BI packages – like Tableau or Pentaho or an in house analytics solution – and they can tell a story from the data. They should also have some level of scientific curiosity.
On the other end of the spectrum, a Data Scientist will have quite a bit of machine learning and engineering or programming skills and will be able to manipulate data to his or her own will.
A Data Scientist should have a wide breadth of abilities: academic curiosity, storytelling, product sense, engineering experience and just a catch-all I call cleverness. But he or she should also have deep domain expertise in Statistical and Machine Learning Knowledge.
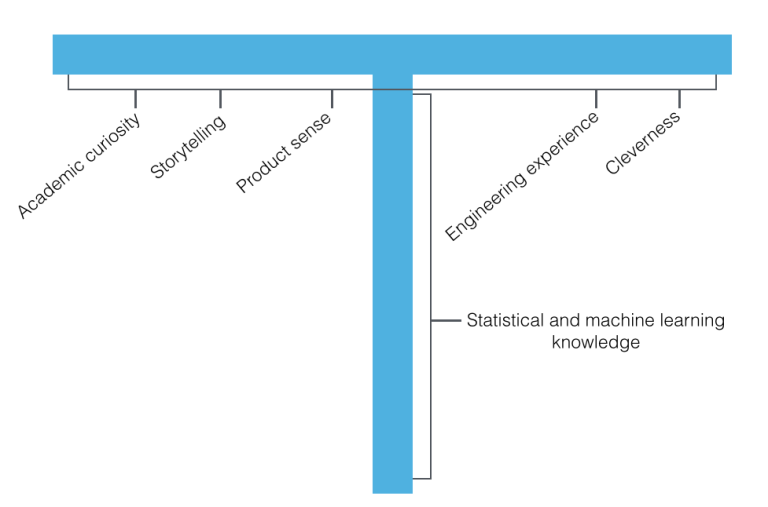
Academic curiosity
To me, academic curiosity is a desire to go beneath the surface and distill a problem into a very clear set of hypotheses that can be tested. Much like how scientists in the research lab will have a very amorphous charter of improving science, data scientists in a company, will have an amorphous charter of improving the product somehow.
He or she will use this academic curiosity to look at the available data sets and sources to figure out an experiment or a model that solves one of the company’s problems.
Storytelling
Storytelling is the ability to communicate your findings effectively to non technical stakeholders.
For example, Mosaic took the entire UK population and ran a machine learning model over it. Based on what they found, they were able to split the entire UK population into 61 clusters. But if you have 61 different clusters, you need a good (easy to explain way) to differentiate between each cluster.
One of those categories is called Golden Empty Nesters, which is a good title because without me explaining anything to you, it evokes some sort of image about the person who would fit into it. Specifically, they are financially secure couples, many close to retirement, living in sought after suburbs.
This ability to distill a quantitative result from a machine learning model into something (be it words, pictures, charts, etc) that everyone can understand immediately is actually a very important skill for data scientists.
Product sense
Product sense is the ability to use the story to create a new product or change an existing product in a way that improves company goals and metrics.
As a Data Scientist at, say, Amazon, it’s not enough to have built a collaborative filter to create a recommendation engine, you should also know how to mold it into a product. For example, the “customers who bought this item also bought” section is an 800 by 20 pixel box which outlines the result of this machine learning model in a way that is visually appealing to customers.
Even if you’re not the product manager – or the engineer that creates these products – as a Data Scientist, whatever you create, in code or in algorithms, will need to translate into one of these products. So having a good sense of what that might look like, will get you a long way.
Statistical and machine learning knowledge
Statistical and machine learning knowledge is the domain expertise required to acquire data from different sources, create a model, optimize its accuracy, validate its purpose and confirm its significance. This is the deep domain expertise in the T shape Data Scientist I mentioned earlier.
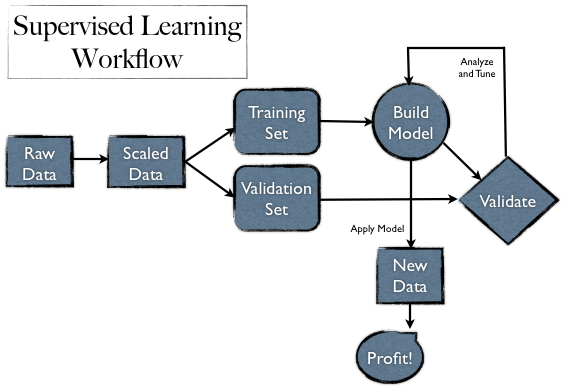
As a Data Scientist, if you know nothing else, you need to know how to take some data, munge it, clean it, filter it, mine it, visualize it and then validate it. It’s a very long process.
Engineering experience
Engineering Experience refers to the coding chops necessary to implement and execute statistical models.
For a lot of big companies this means knowing intense amounts of Scala, Java, Closure, etc. to deploy your models into production. For startups this can be as simple as implementing a model in R.
Consequently, R is a great language for scaffolding models and visualization, but it’s not so great for writing production ready code – it breaks whenever you throw anything more than 10 megabytes in front of it.
But, it’s a great language to set up a proof of concept, and the ability to create something out of nothing and to prove that it works, is a skill that I think most data scientists ought to have.
Timely Optimization
The last skill on my list I call cleverness, or the creativity to do all these things on a deadline or on constrained resources.
The difference between research scientists in academia and Data Scientists in the real world, is that scientists in academia (given funding) have all the time in the world to figure out problems. The whole point of academia is to move the boundary of knowledge forward at all cost.
The goal of a Data Scientist in a startup or a tech company, is to move the product forward at minimal cost, yesterday. So the ability to take on deadlines, constrained resources – even your company’s political climate – and push a product out in a reasonable amount of time is a really important skill.




